


Faster Way To Create List From Stream
In recent years functional programming (FP) has become very popular. FP is also one of the main reasons for introducing streams in Java. As a result, developers started replacing loops with streams. As we are working with web services, and those services usually move data, it is usual to map data between different objects.

In recent years functional programming (FP) has become very popular. FP is also one of the main reasons for introducing streams in Java. As a result, developers started replacing loops with streams.
As we are working with web services, and those services usually move data, it is usual to map data between different objects. If you are writing clean code, that mapping would be extracted into a function. That function would look like the following code (for mapping implemented using stream):
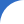
<strong>private </strong>List<B> mapToB(List<A> list) { <br /> <strong>return</strong> <br /> list <br /> .stream() <br /> .map(<elementMappingFunction>) <br /> .collect(Collectors.toList()); <br />} This code is very easy to write, and it is also very readable. But, there is one improvement that can make this code run even faster. In order to figure out how to implement it, let’s first check what the method Collectors.toList() looks like:
From the code above, we can see that a new instance of the CollectorImpl class is created. It has the following arguments:
- Initial value – in this case, is an empty array list
- Accumulator function- is in this case the pointer to the function List: add
- Combiner function – this simply adds all the elements to the left array list from the right array list
- Set of characteristics, this parameter is not important for the current discussion
“Lazy” Array List
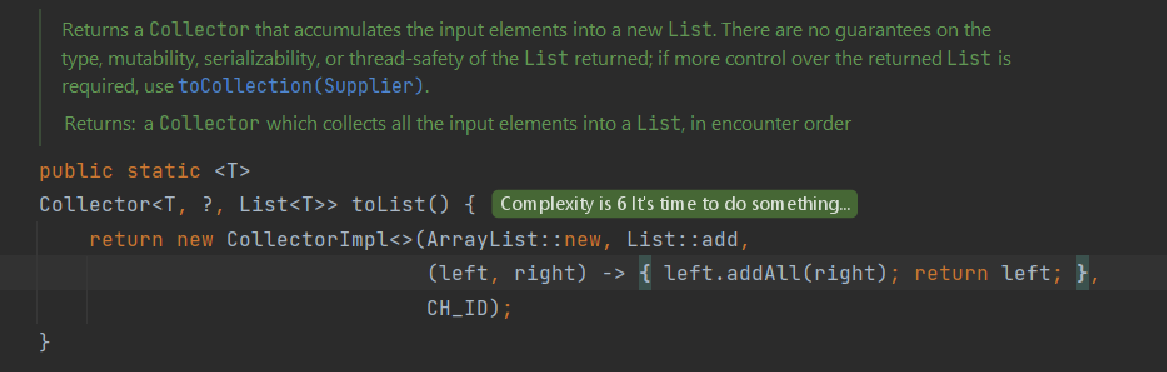
Now, there is something that ‘smells’ here, it is the first initial value. We don’t provide the initial size for the array list at the moment of initialization. So, what is the initial capacity for the newly created array list? Again, let’s check the source code:
We can see that every instance of the ArrayList class starts with the pointer to the empty array. This is good because it means that arrays are “lazily” initialized, i.e. they don’t consume any memory space until the moment when they actually need it. We need to investigate further… Let’s see what happens when new elements are added to the empty array list:
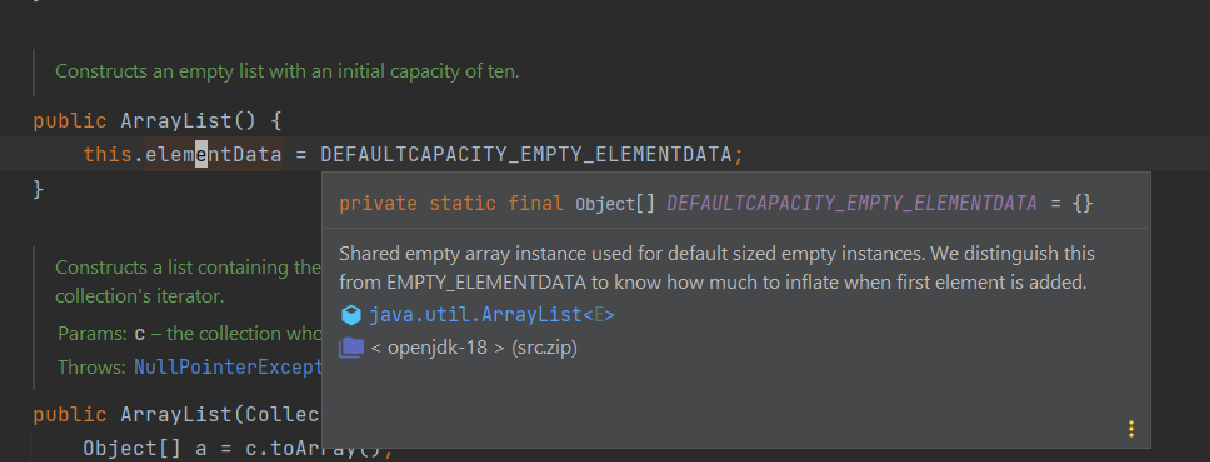
The algorithm for adding a new element has two main branches:
- If there is space for adding a new element, a new element is added to the end of an array. The pointer to the last element is also updated and now points to a newly added element
- In the case, that the array has no space, it needs to be expanded and the method grow is called into action. Let’s see how the method is implemented:
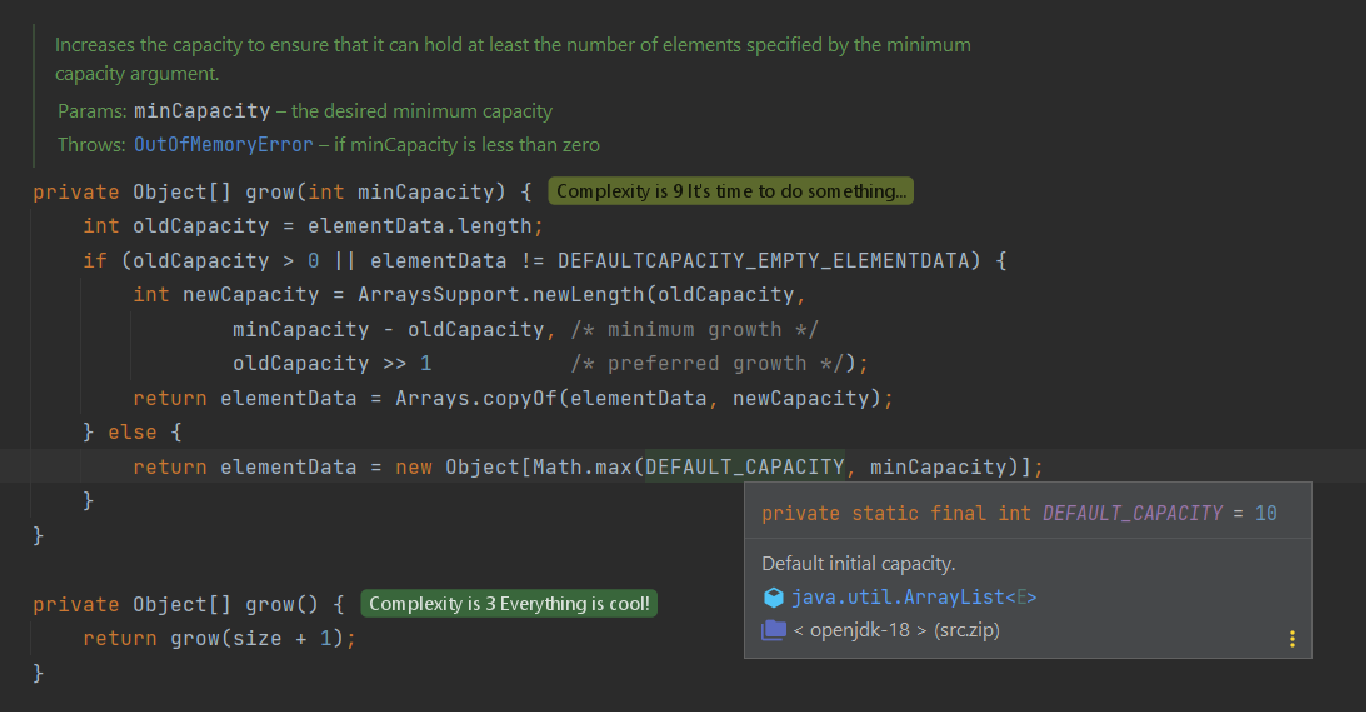
We can see in this method that when a first element is added to a List, a new array is initialized in a memory with the default size of 10. Afterward, when the array needs to be expanded, the new size is calculated through the following formula:
newCapacity = oldCapacity >> 1 This means increasing the size of the array by 50%. This formula can be mathematically written as:
newCapacity = oldCapacity + oldCapacity/2. If we want to copy an array with 1000 elements there will be 17 array capacity increases. This means it is needed to allocate new memory and copy the data on a new memory location 17 times. Garbage Collector (GC) also needs to free up those old memory allocations, and it also needs to consume some CPU cycles.
Better alternative
Because we have multiple memory allocations and memory copy actions, the better alternative would be to provide the initial size to an array that is being created. We can change the implementation into:
<strong>private</strong> List<B> mapToB(List<A> list) { <br /> <strong>return</strong> <br /> list <br /> .stream() <br /> .map(<elementMappingFunction>) <br /> .collect(Collectors <br /> .toCollection(() -> <strong>new</strong> ArrayList<>(list.size()))); <br />} This is the ‘uglier’ implementation, but in theory, it should be faster. Let’s check if the theory is proven in practice by measuring the performance.
I created the benchmark using the JMH library. In the beginning, there is one array of random numbers. It has a length of 10.000 elements. I have tried different sizes for the array, but the performances increase and decrease linearly (which is a good sign). Then, I created two methods for mapping that random array to a new array. In both methods, I’m using the stream and map method. After that, results are collected from the stream and returned from the mapping method. As JVM runtime I used OpenJDK 18.
- In the first method, I collected results without specifying the number of elements (Collectors.toList())
- In the second method, I specified the number of elements (Collectors.toCollection(new ArrayList(inList.size())))
In order to include the effect of garbage collection, I used a serial garbage collector ( with the argument –XX:+UseSerialGC). I also limited the amount of JVM memory to 3MB. I run 20 iterations, each lasting 10 seconds on my PC and got the following results:
Collectors.toList() thrpt 690.133 ± 3.093 ops/s
Collectors.toCollection(..) thrpt 1108.133 ± 4.194 ops/s
As we can see, there is a significant difference in performance. When the initial size is not specified, we have 690 operations per second, compared to the 1108 ops/s when it is specified. Based on those results, we can say that the Collectors.toCollection(..) is nearly 2 times faster.
This difference in time is not that significant when we use a different garbage collector. This happens because garbage collection in Java is multi-threaded. Still, Java needs to do more work in order to clean up all that extra allocated memory.
Custom utility method
As for the ‘ugliness’ part, we can create a custom utility method and make our lives easier:
<strong>public</strong> <strong>class</strong> MyCollectors { <br /> <strong>public</strong> static <T> Collector<T, ?, List<T>> toList(int size) { <br /> <strong>return</strong> Collectors.toCollection(() -> <strong>new</strong> ArrayList<>(size)); <br /> } <br />} Even if an array is not very big, if we don’t specify the allocation size we will still probably have some unused space in an array. Again, bypassing the size of the array constructor, we can save memory. For example: if we have an array of 6 elements, ArrayList will allocate memory space for 10 elements, and memory for 4 elements will be unused.
One question arrives based on this discussion:
If the performance is so much better when we specify the length to the ArrayList constructor, why doesn’t a collector that has size as a parameter already exists?
I don’t really know the answer to this question. I suppose that the reason behind it is because of the nature of the streams. In most cases, the total number of results that will be collected is not known in advance. And this is the limit for this use case. If you don’t know the expected size of a resulting array, then I don’t recommend specifying the length because Java already has a very good algorithm to grow arrays. This leads me to think that maybe we can implement some AI algorithm to predict the size of an array.
Below is the code that is used for performance testing:
@Fork(warmups = 0, value = 1, jvmArgsPrepend = {"-Xmx3m"}) <br />@BenchmarkMode(Mode.Throughput) <br />@OutputTimeUnit(TimeUnit.SECONDS) <br />@Measurement(time = 10, iterations = 20) <br />@Warmup(iterations = 10, time = 10) <br /><strong>public</strong> <strong>class</strong> CopyAndMapListPerformance { <br /> <br />@State(Scope.Benchmark) <br /><strong>public</strong> static <strong>class</strong> InputParams { <br /> @Param({"10000"}) <br /> int noOfItems; <br /> <br /> <strong>private</strong> List<Integer> inList; <br /> <br /> <strong>public</strong> InputParams() {} <br /> <br /> @Setup(Level.Trial) <br /> <strong>public</strong> void createRandomList() { <br /> Random r = <strong>new</strong> SecureRandom(); <br /> inList = <br /> IntStream <br /> .range(0, noOfItems) <br /> .mapToObj(i -> r.nextInt()) <br /> .collect(Collectors.toList()); <br /> } <br /> } <br /> <br /> <strong>public</strong> static <strong>class</strong> OutClass { <br /> Integer data; <br /> OutClass(Integer data) { <br /> <strong>this</strong>.data = data; <br /> } <br /> } <br /> <br /> @Benchmark <br /> <strong>public</strong> List<OutClass> noSizeParamForLoop(InputParams state) { <br /> ArrayList<OutClass> list = <strong>new</strong> ArrayList<>(); <br /> <strong>for</strong> (int i = 0; i < state.inList.size(); i++) { <br /> list.add(<strong>new</strong> OutClass(state.inList.get(i))); <br /> } <br /> <strong>return</strong> list; <br /> } <br /> <br /> @Benchmark <br /> <strong>public</strong> List<OutClass> sizeParamForLoop(InputParams state) { <br /> ArrayList<OutClass> list = <strong>new</strong> ArrayList<>(state.inList.size()); <br /> <strong>for</strong> (int i = 0; i < state.inList.size(); i++) { <br /> list.add(<strong>new</strong> OutClass(state.inList.get(i))); <br /> } <br /> <strong>return</strong> list; <br /> } <br /> <br /> @Benchmark <br /> <strong>public</strong> List<OutClass> noSizeParamStream(InputParams state) { <br /> <strong>return</strong> state.inList <br /> .stream() <br /> .map(OutClass::<strong>new</strong>) <br /> .collect(Collectors.toList()); <br /> } <br /> <br /> @Benchmark <br /> <strong>public</strong> List<OutClass> sizeParamStream(InputParams state) { <br /> <strong>return</strong> state.inList <br /> .stream() <br /> .map(OutClass::<strong>new</strong>) <br /> .collect(Collectors <br /> .toCollection(() -> <strong>new</strong> ArrayList<>(state.inList.size()))); <br /> } <br />} Thank you for reading this article.
If you liked it, follow me on Twitter.
Author of the text: Marko Milenkovic

You may also like

Streamline your Workflow with Spreadsheet
July 19, 2024

Mastering Business Development in the IT industry: Essential Tips and Tricks
April 10, 2024

From the Code to the Conference
March 7, 2024

My First Salary as the First Step Towards a Career in IT: Testimonials & Advice
December 4, 2023

Nurturing Growth Through Mentorship: Three Teams, One Name
October 9, 2023

Mirror Neurons: Do They Help Us be Better Leaders?
April 3, 2023

Saveti naših koleginica – Šta biste rekle mlađoj verziji sebe?
March 8, 2023

Cracking the Backend Code: Tips and Tricks from Our Devs
February 13, 2023

Project Valhalla – “Codes like a class, works like an int.”
January 26, 2023

Mitovi o psihoterapiji
January 20, 2023